Blocking과 Non-Blocking, Sync와 Async 개념은 뭐랄까.. 이해한 것 같다가도 오랜만에 보면 헷갈리고, 알 것 같다가도 섞어서 보면 또 모르겠더군요🤔
한 번 확실히 짚고 넘어가면 좋겠더라고요. 마침 적절한 비유까지 떠올라서 글을 작성해봤습니다.
저는 사무실에 있습니다. 복합기를 사용해서 스캔을 뜨고 싶습니다. 그런데 문서의 양이 많아서 시간이 좀 오래 걸립니다. 10분 이상 걸린다고 해볼까요.
복합기의 시작 버튼을 눌렀습니다. 그리고 그 앞에서 스캔이 완료될때까지지 하염없이 기다렸다가 결과물 스캔 된 파일)을 갖게 된다면, 이것은 blocking 입니다. 10분은 아무것도 안 하기에는 꽤 긴 시간인데 말이죠. blocking 방식에는 다른 일을 모두 중지하고 작업이 완료되기 만을 오매불망 대기하는 이 기다림이 항상 포함되어 있습니다.
반면 non-blocking은 기다림이 없습니다. 시작 버튼을 눌러 놓고 뭔가 다른 일을 합니다. (Hopefully, 함수 하나 정도 리팩토링해 봅시다) 다시 힐끗 확인 했을 때 아직 스캔 중이라면, 잠시 잊어버리고 다시 다른 일에 집중합니다. 조금 있다가 또 힐끗 확인 했을 때 완료되었다면, 이제 결과물을 가질 수 있습니다.
이 짓거리(?)를 내가 직접 한다면 synchronous(이하 sync) 입니다. 반면 내가 직접 하지 않고 다른 누군가를 시킨다면 asynchronous(이하 async) 입니다.
정리하자면 이렇습니다.
- 기다림 Blocking / 기다리지 않음 Non-blocking
- 내가 함 Synchronous / 다른 사람 시킴 Asynchronous
사족을 좀 붙이자면, 우리가 종종 non-blocking과 async를 헷갈리는 이유는 둘 다 어쨌거나 '내가 기다림으로부터 자유롭다'는 공통점 때문인 것 같습니다. 그래서 이 비유를 일부러 넣었습니다. 비유를 통해서 차이가 더 분명하게 보이기를 기대하면서요.

짤은 그냥 넣어봤습니다.
#섞어보기
이 개념들의 묘미는, 두 가지의 서로 다른 개념을 섞었을 때 옵니다. 이제 섞어보겠습니다.
-
Sync-Blocking
앞의 blocking 설명과 사실상 동일합니다. 내가 복합기 앞으로 갑니다. 시작 버튼을 누릅니다. 다른 일 못하고 기다립니다. 완료되면 그제야 내 자리로 돌아가 스캔 완료된 파일을 사용합니다. -
Sync-NonBlocking
앞의 non-blocking 설명과 동일합니다. 내가 복합기 시작 버튼을 누릅니다. 자리로 돌아옵니다. 틈틈이 스캔이 완료되었는지 확인해줘야 합니다. 하지만 다른 일을 할 수 있습니다. 다른 일을 못 하면서까지 앞에 가서 기다리지는 않습니다. -
Async-Blocking
드디어 심부름꾼이 등장합니다. 나는 내 자리에 그대로 앉아있습니다. 나는 다른 일을 하는 동안, 심부름꾼에게 스캔을 하도록 시킵니다. 심부름꾼이 복합기 앞으로 갑니다. 시작 버튼을 누릅니다. 이 사람은 다른 일 못하고 이것만 기다립니다. 완료되면 심부름꾼은 내 자리로 돌아와 스캔이 완료되었다고 알려줍니다. -
Async-NonBlocking
나는 내 자리에 앉아서 내 일하는 동안, 심부름꾼에게 스캔을 하도록 시킵니다. 심부름꾼이 복합기 앞으로 가서 시작 버튼을 누릅니다. 심부름꾼은 스캔을 기다리면서 커피를 내려 마시면서 일기를 씁니다. 일기를 쓰는 동안, 틈틈이 스캔이 완료되었는지 곁눈질로 확인합니다. 스캔이 완료되면 내 자리로 돌아와 스캔이 완료되었다고 알려줍니다.
#이렇게 나누는 게 무슨 의미가 있나?
그러면 여기서 생각해보겠습니다. 위의 네 가지 케이스 중에서, 두 사람의 '시간'이라는 자원을 가장 효율적으로 사용한 경우는 무엇일까요?
아래의 그림을 보시면 명확합니다. 아무것도 하지 않고 기다리는 시간(또는 중간에 스캔이 완료되었는지 체크하는 시간)을 빈칸으로, 다른 작업 중인 시간을 색칠된 칸으로 나타냈습니다. 한마디로, 색칠된 면적이 클수록 시간을 효율적으로 사용했다고 볼 수 있습니다. 좀 단순화시키기는 했지만요.
Async-NonBlocking이 가장 효율적이고, Sync-Blocking이 가장 비효율적이라고 볼 수 있겠네요.
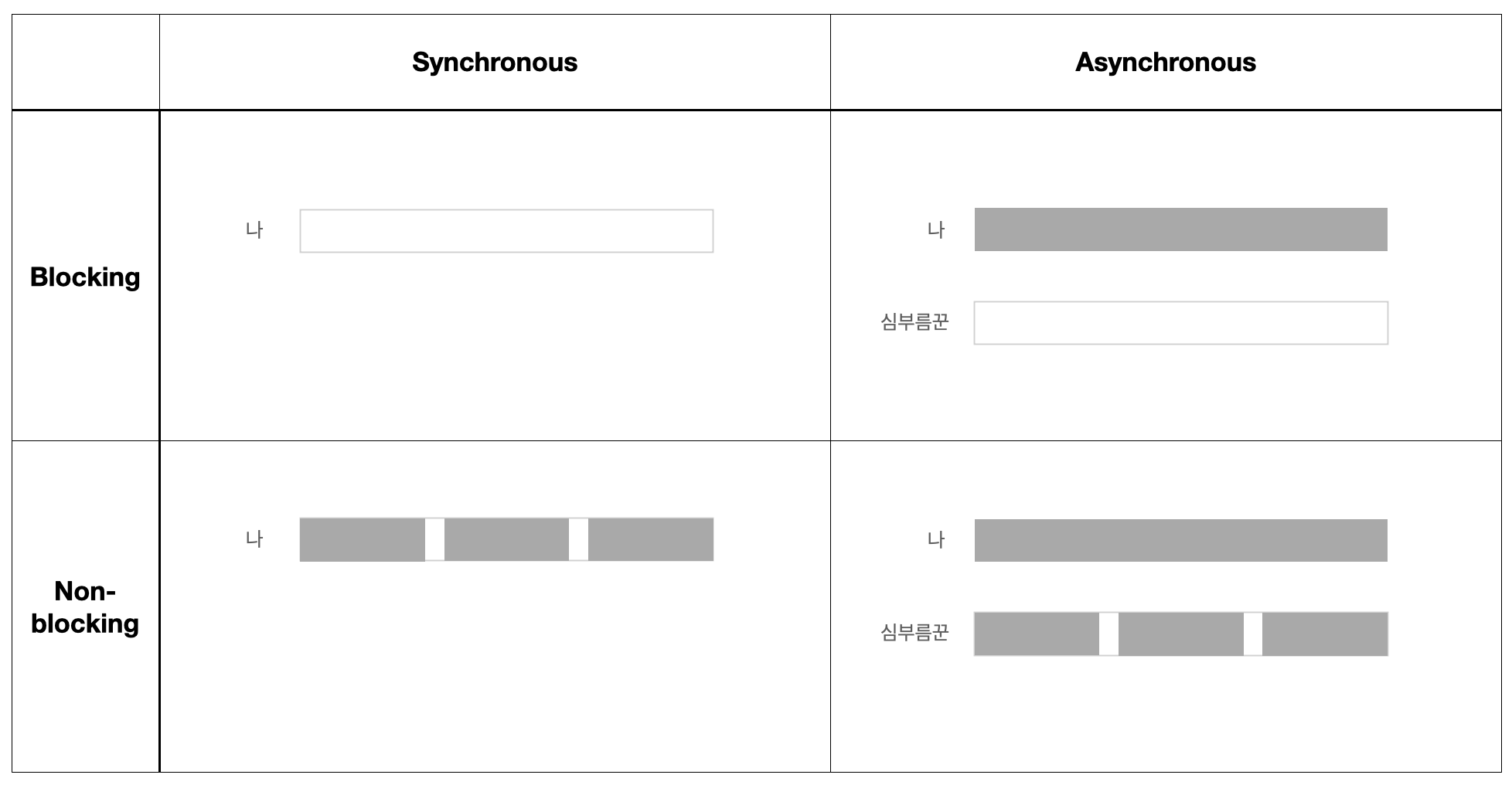
제가 여기서 '시간' 비유를 통해 나타내고 싶었던 주인공은 사실, 'CPU'입니다. 컴퓨터에서 아무것도 하지 않고 있는 시간은 곧 CPU의 낭비라고 볼 수 있으니까요. 촘촘하게 시간을 사용한다는 것은 곧 CPU라는 컴퓨팅 자원을 효율적으로 사용한다는 뜻입니다. 그렇다면, Async-NonBlocking 방식을 사용할 때 가장 효율적이라는 결론이 나오네요.
#운영체제의 입장에서
이제 비유를 빼고, 운영체제의 입장에서 개발의 언어로 다시 말해보겠습니다.
I/O 요청은 파일 읽기와 같은 디스크 I/O 요청, 소켓으로부터 읽기와 같은 네트워크 I/O 요청 등이 있는데요. CPU의 입장에서는 매우 시간이 오래 걸리는 작업입니다.
I/O 요청을 blocking으로 처리한다는 것은, 프로세스가 I/O를 위한 시스템 콜을 한 뒤 sleeping이나 waiting 상태로 들어간다는 의미입니다. 그동안 프로세스는 CPU를 놓아주고 아무것도 하지 않는 상태가 됩니다. I/O 처리가 완료되고 요청한 데이터가 준비되면, 그때 인터럽트가 발생해 프로세스가 재개됩니다.
반면 Non-blocking I/O는 CPU를 놓지 않습니다. Non-blocking 옵션으로 시스템 콜을 호출하게 되면, 아직 I/O가 완료되지 않았다면 falsy한 값을 반환받습니다. 시간이 걸리는 I/O 요청을 처리하는 동안 이 CPU 자원을 이용해서 다른 작업을 하고 있을 수 있습니다.
Sync는 메인 흐름에서 순차적으로 처음부터 끝까지 처리합니다. 반면 별도의 스레드를 만들어서 처리하거나, 이벤트 핸들러, 콜백 함수 등을 사용하는 경우를 async라고 할 수 있습니다.
정리하자면 이렇습니다.
- CPU를 놓음 Blocking / CPU를 놓지 않음 Non-blocking
- 같은 흐름에서 처리 Synchronous / 다른 흐름에서 처리 Asynchronous
개념을 이해하는 데에 제 비유가 도움이 되었다면 좋겠네요!
#References
- Real Linux의 '리눅스 SW 기본반' 강의 내용을 일부 참고해서 작성했음을 밝힙니다.
